
在人工智能领域,Transformer架构、大模型是当下最激动人心的话题之一。它们不仅推动了技术的极限,还重新定义了我们与机器交互的方式。本文将带您从科普的视角了解这些开启智能新篇章的概念。Transformer模型最初由Google的研究人员在2017年提出,它是一种基于自注意力机制的深度学习模型,用于处理序列数据。在此之前,序列数据处理主要依赖于循环神经网络(RNN)和长短期记忆网络(LSTM),但这些模型在长距离依赖和并行计算方面存在限制。

Transformer的自注意力机制允许模型在处理序列的任何元素时,同时考虑序列中的所有其他元素并给出不同元素的重要程度。想象一下,你是一位导演,正在一部舞台剧中指导一群演员。在任何给定的场景中,你都需要决定哪个演员应该成为观众注意的焦点。这时,你会用一束聚光灯照亮你想要突出的演员,而其他演员虽然仍在舞台上,但会处在较暗的背景中。注意力机制在人工智能中的作用就像这个“聚光灯”,它帮助模型确定在处理大量数据时应该“照亮”哪些信息。在自然语言处理的语境中,比如在阅读一篇文章时,模型需要理解每个单词的意义及其在文中的重要性。不是所有的单词都同等重要,有些单词对于理解句子的意思至关重要,而有些则不那么重要。注意力机制允许模型动态地调整它对不同单词的“聚焦”程度,就像导演控制聚光灯一样,让某些单词在模型的“视野”中更加突出。

在具体实现上,每个单词(或数据点)都会被分配一个权重,这个权重代表了它在当前上下文中的重要性。模型通过这些权重来决定在生成输出时应该“照亮”哪些单词。比如从英语翻译到中文,模型会在翻译每个中文词时,重新计算这个分数,以确保聚光灯始终对准最相关的英文词。这种动态调整允许模型即使在面对很长的输入序列时也不会丢失重要信息。这就好比一个翻译员在翻译一句长句子时,她会时不时回头查看原文的某些部分,以确保翻译的准确性和连贯性。
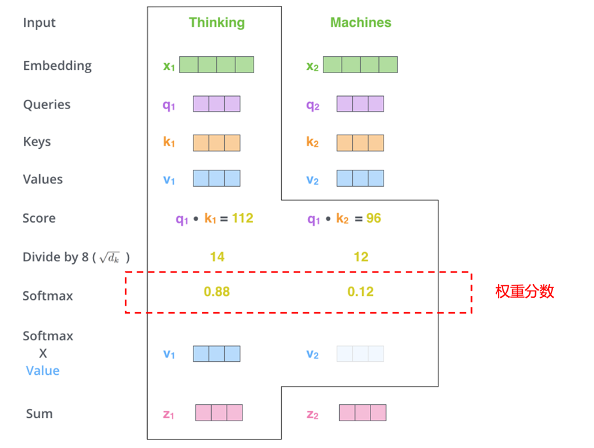
通过注意力机制,模型能够更好地处理复杂的模式和长距离的依赖关系,这种能力极大地提高了模型在语言理解、情感分析、语音识别等复杂任务中的表现,并且不断推动着人工智能技术的发展和创新。Transformer又可以分为Encoder(编码器)和Decoder(解码器)。其中,Encoder将一段话或者一张图利用注意力机制转换成向量的形式,这个向量包含了这段话或图的所有信息,AI模型便可用这个向量来进行分类或者回归的任务。
发表回复